
Four pillars that are crucial to a successful data mesh initiative
For health data executives, implementing a data mesh requires re-engineering data flows with a structured approach.

Modern healthcare enterprises operate within a paradoxical data reality. Our systems are drowning in petabytes of digital assets, but yet our clinical and operational leaders remain functionally starved for actionable insights.
The digital transformation of healthcare — accelerated by federal interoperability mandates, the maturation of electronic health records (EHRs), the explosion of remote patient monitoring IoT devices and the clinical integration of high-throughput genomic sequencing — has generated an unprecedented deluge of data.
Yet, traditional enterprise data frameworks are fundamentally failing to deliver on the promise of this asset. Monolithic centralized data lakes and legacy enterprise data warehouses have converted data management into an operational bottleneck. In these legacy paradigms, a centralized IT department or a core data engineering team is tasked with ingesting, cleaning, modeling and serving data from hundreds of disparate clinical, financial and operational systems.
This centralized model breaks down because a core IT team cannot possess the deep, highly specialized contextual knowledge required to interpret data from a diverse array of medical domains. A corporate IT generalist cannot accurately differentiate between an artifactual baseline shift and a true ventricular tachycardia in streaming telemetry logs. Nor can a central engineer intuitively navigate the complex, localized logic of revenue cycle management or the niche metadata structures inherent to 3D radiological imaging.
The inevitable result of this structural mismatch is a perpetual engineering backlog, degraded data quality, fractured clinical trust and a systemic inability to rapidly deploy predictive analytics or immediate feedback loops at the point of care.
The macro-shift: Transitioning to the mesh
To unlock the true clinical, operational and financial value of modern digital health assets, healthcare data leadership must undergo a foundational structural shift. We must move away from centralized data monocultures toward a data mesh architecture.
Pioneered by Zhamak Dehghani, data mesh is a decentralized, sociotechnical paradigm that treats data not as an accidental, passive byproduct of transactional applications, but as an active, domain-driven product managed and owned by those who know it best.
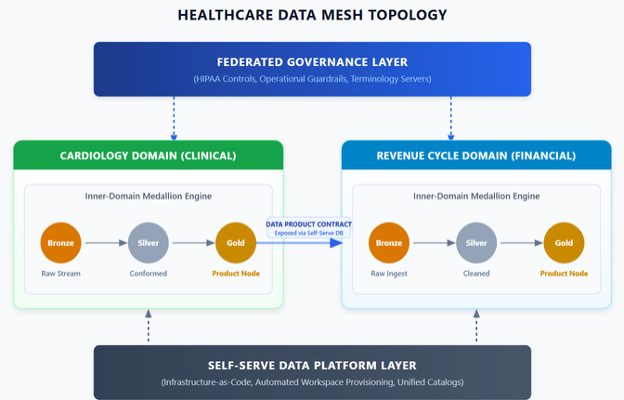
For a health data management executive, implementing a data mesh requires re-engineering data flows around four core, interconnected pillars.
Domain-driven decentralized data ownership
In legacy architectures, data is extracted from domain source systems (like an Epic or Cerner EHR) and dumped into a central repository where the operational teams wash their hands of it. In a data mesh, ownership of the data never leaves the domain.
A domain is a logical grouping of business or clinical capabilities. In healthcare, these map directly to functional areas — clinical domains (cardiology, oncology, radiology); operational domains (supply chain, bed utilization); and financial domains (revenue cycle management).
Under this model, the cardiology department does not simply generate data for the electronic medical record; it owns the analytical representation of that data. The domain is staffed not only with clinicians, but with embedded data engineers who intimately understand the clinical nuances of their specific datasets.
Data as a product
When data is treated as a product, downstream data consumers — such as data scientists training clinical AI, population health analysts and operational dashboard developers — are viewed strictly as customers. The domain data team is explicitly responsible for the discoverability, quality, security and usability of their datasets.
A healthcare data product is a self-contained functional unit consisting of the ingest pipelines, the underlying high-performance storage and the necessary access endpoints. Crucially, these products must come with an explicit, enforceable service level agreement (SLA). For instance, the emergency department domain might publish an "inpatient acuity and wait times" data product. The SLA guarantees that the data is refreshed every five minutes, adheres to strict schema validations and contains zero unmapped local billing codes.
Self-serve data infrastructure as a platform
Decentralizing data ownership to clinical lines sounds operationally terrifying. A clinical nurse manager or a cardiology fellow should not be managing database clusters or configuring complex identity management roles. This is where the self-serve data platform comes in.
The data platform team is a centralized unit, but they do not touch, clean or own the data. Instead, they build and maintain an automated, self-serve platform that abstracts away all infrastructure complexities. Through automated blue-printing tools and infrastructure-as-code templates, a clinical domain team can click a button to provision a fully compliant, isolated data workspace complete with encrypted object storage, access to a central schema registry and automated connections to the enterprise data catalog.
Federated computational governance
Healthcare operates under a strict regulatory umbrella dominated by HIPAA, HITECH and evolving state-level privacy protections. In a decentralized architecture, a traditional centralized governance board becomes a bureaucratic logjam, while completely unguided domain autonomy results in non-compliance and systemic data fragmentation.
Federated computational governance resolves this by bringing domain representatives together into a central steering council to define global policies. Crucially, these policies are not left as static text documents on an intranet site — they are converted into code and enforced computationally by the self-serve platform. If the governance council mandates that all patient health information must be automatically masked at rest for non-clinical consumers, this policy is baked directly into the platform’s deployment pipelines. Any data product spun up by a domain automatically inherits these compliance guardrails, rendering it secure by default.
The architectural conflict ahead
By shifting accountability to the local level where the data is actually understood, the data mesh offers a scalable blueprint for the future of digital health. However, implementing this architecture within a health system requires navigating deep technical friction points unique to our industry.
When organizations attempt to engineer this mesh, they almost universally fall into a dangerous trap — trying to use transactional exchange standards as the core analytical engine of the mesh or accidentally rebuilding a centralized data monolith under a different name.
In Part 2 of this series, we will examine the "boundary thesis" and tackle the reality check of why HL7 FHIR — while an unmatched standard for operational exchange — fails when forced to act as an analytical core.
Aaron Seib, PMP, FACHDM, CDMP-practitioner, is chief data interoperability officer at Goldbelt Apex LLC, and former senior vice president of strategy and innovation for NewWave Telecom & Technologies.